

Rails Benchmarking: Puma and MultiProcess
/This week, I've been playing with Puma processes. Headius, Nate Berkopec, you can probably stop reading now. You won't learn much ;-)
One consequence of the GIL is that a single Ruby process has limited ability to fully use the capabilities of a multi-core machine, including a larger AWS instance.
As a result, the optimum number of Rails processes for your AWS instance is probably not just one.
I'm still using my Discourse-based Rails benchmark, and we'll look at how the number of processes affects the total throughput. There are some slightly odd things about this benchmark that haven't changed since previous articles. For instance, the fact that Postgres and the load-testing process runs on the same machine as Puma. The load-testing process is singular now with only threads, which helps its impact noticeably.
A quick note on Puma: by default it will spawn threads on demand in a single Ruby process with a single GIL, up to a maximum of 16 or whatever you specify. In cluster mode it will spawn more Ruby processes, as many as you specify, each one having on-demand threads up to 16 or the number you picked.
Workers and Speed
In a previous post I played with load-testing threads to find out what it took to saturate Puma's default single process with a single GIL. In this post, I'll talk a bit more about what it takes to saturate an EC2 t2.2xlarge instance with Rails, database and load-testing processes.
With a single load-testing process and one Rails worker, you can get reasonable gains in total speed up to 5-7 load-testing threads. But there are two hyperthreaded cores on the instance, for a total of somewhere between 2 and 4 effective cores. We're already running five load-testing threads, one Rails thread, Postgres, and a normal collection of Ubuntu miscellaneous processes. Aren't we close to saturated already?
(Spoiler: not hardly.)
Per Aspera Ad Astra
Our time to process 1500 total requests with one Rails process was around 35 or 36 seconds. There's a bit of variation from run to run, as you'd expect. That involved adding more load-testing threads to generate more requests. Even a single process, with a GIL preventing simultaneous Ruby, still likes having at least 5 or so load-testing threads to keep it fully loaded.
How about with two processes? To process the same total number of requests, it takes 17 to 19 seconds, or around half the time. That's nice, and it implies that Rails is just scaling linearly at that point. It won't scale perfectly forever due to things like database access and a limited number of cores, but it's pleasant while it lasts. So clearly having two processes of 16 threads is a win for Rails throughput.
How about three processes? 13-14 seconds to process all 1500 requests, it turns out. And you can be sure that part of the delay there is in the load tester (remember, still only five load threads with a GIL), not the Rails server.
But what if we crank it up to 20 load threads? And 11 Puma processes, just to keep things interesting... And to process every request, it takes between 5.5 and 7.0 seconds, roughly. I wasn't expecting that when we started with a (tuned) one-Rails-process server at the beginning. Were you? Heck, at that level you have to wonder if the GIL is slowing things down *in the load tester*.
So go for broke: what about 30 load threads and 11 Puma processes?
Finally, at this point, we start seeing fun 500 errors, which you'd kind of expect as you just keep cranking things up. Postgres has a built-in limit of 100 connections (configurable upward), and 11 Puma processes with up-to-sixteen-on-demand threads for each one, plus the load testers, is finally exceeding that number. As a corollary, the previous 11 Puma threads with only 5 load threads were clearly not using all 16 threads per server -- if they did, we'd have hit this Postgres limit before, since 11 * 16 is more than 100.
Between you and me, I did have a breakage before that. I had to increase the number of ActiveRecord threads, called "pool", in database.yml before I hit Postgres' limit.
This all suggests an interesting possibility: what about limiting the number of threads per process with the higher number of processes? Then we can duck under the Postgres limit easily enough.
One More Time
Let's look at some (very) quick measurements on how fast it runs with different combinations of processes and threads...
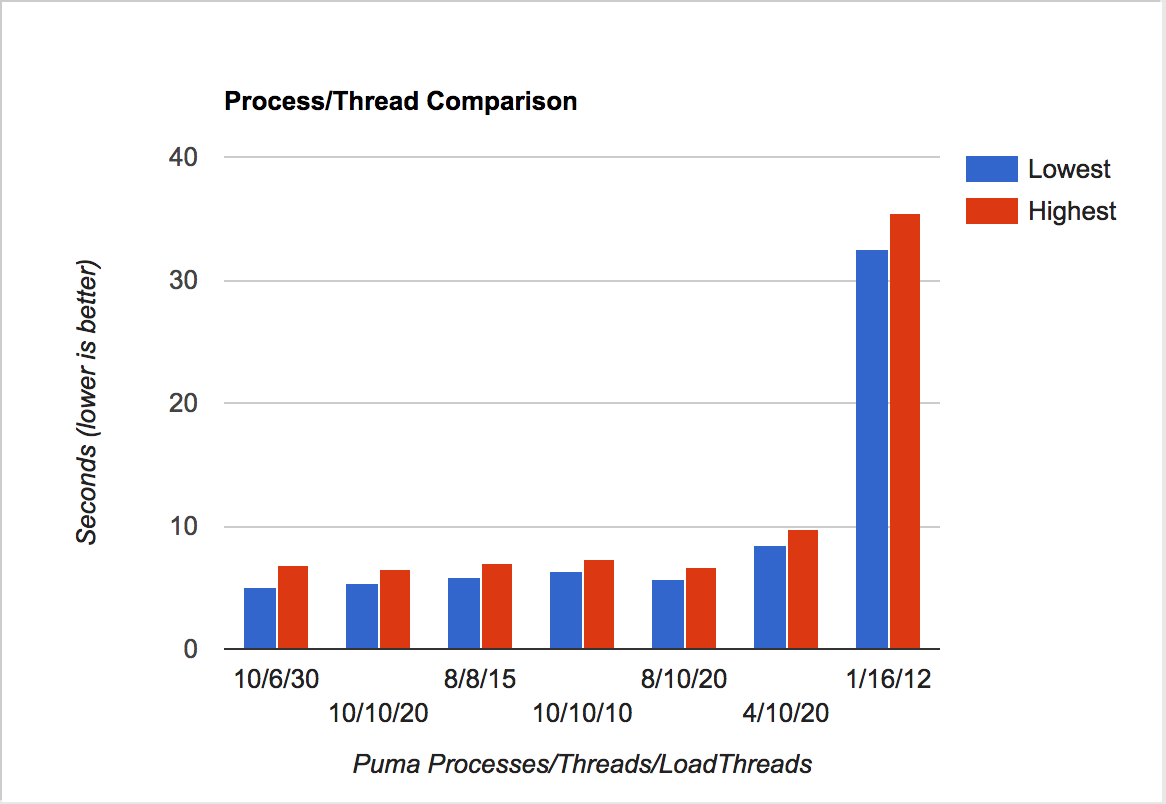
Performance by number of Puma threads and processes, and by load-testing threads.
| Puma Processes | Puma Threads | Load Threads | Time Taken |
|---|---|---|---|
| 10 | 6 | 30 | 5.1 - 6.8 |
| 10 | 10 | 20 | 5.3 - 6.5 |
| 8 | 8 | 15 | 5.8 - 7.0 |
| 10 | 10 | 10 | 6.3 - 7.3 |
| 8 | 10 | 20 | 5.7 - 6.7 |
| 4 | 10 | 20 | 8.5 - 9.7 |
| 1 | 16 | 12 | 32.6 - 35.5 |
(Note: all of this is done with current-latest Rails Ruby Bench and Ruby 2.3.1p112 - having some compatibility issues with latest 2.4.0 and latest Discourse release because of JSON 1.8.3 incompatibility. Working on it!)
To keep under the Postgres 100-connection limit, use threads for quick context switching and more processes for avoiding the GIL, there's a pretty good sweet spot at around 30 load-testing threads, 10 Puma processes and a limit of 6 threads/process. At that point, the noise in the benchmark starts to make it hard to tell whether a new configuration is faster -- there's too much noise and too little change. There's a tool to get around that, but for now, it's time to move to a different issue.
For now, let's call that success on tuning processes and threads. Later it's highly likely that the load-tester is hitting GIL contention with 30 (!) threads, and I'm *sure* this quick-and-dirty configuration check isn't the very fastest way to serve 1500 requests in Rails. But we've verified that anything starting at around 8-10 Puma processes, 5 processes/thread and 20+ load testing threads will get us into quite decent performance (5-8 seconds for 1500 requests.)
But this is definitely the low-hanging fruit, and a solid configuration. And we don't need or *want* it to be perfect. We want it to be a representative configuration for a "normal" "real" Rails app, laboring hard. Speaking of which...
Ruby 3x3
Even this little two-to-four-core EC2 instance is clearly benefiting a lot from having lots of Ruby threads running at once. That's a really good sign for Ruby Guilds. It's also great for JRuby, which has the JVM's world-class thread performance and no GIL. Expect me to time JRuby in a future post, after adding some warmup iterations to keep JRuby's JIT from making it look incredibly slow here. 1500 requests just isn't that much, and even for MRI the total number may need an increase.
Later, it's likely I'll reimplement the load tester to use clustered processes with many worker threads. I think the load tester is a *great* place to use guilds once they become available, and to measure their performance when it's time to. But there may be some interesting difference between multithreaded speed and Guild speed, depending on what objects are accessed...
Hope you've enjoyed reading about this Rails benchmark performance! I'll keep writing as it evolves...