How Much Do You Save With Ruby 2.7 Memory Compaction?
/If you read this blog recently, you may have seen that Ruby Memory Compaction in 2.7 doesn’t affect the speed of Rails Ruby Bench much. That’s fair - RRB isn’t a great way to see that because of how it works. Indeed, Nate Berkopec and others have criticised RRB for that very thing.
I think RRB is still a pretty useful benchmark, but I see their point. It is not an example of a typical Rails deployment, and you could write a great benchmark centred around the idea of “how many requests can you process at most without compromising latency at all?” RRB is not that benchmark.
But that benchmark wouldn’t be perfect for showing off memory compaction either - and this is why we need a variety of performance benchmarks. They show different things. Thanks for coming to my TED talk.
So how would we see what memory compaction does?
If we wanted a really contrived use case, we’d show the “wedged” memory state that compaction fixes - we’d allocate about one page of objects, free all but one, do it over and over and we’d wind up with Ruby having many pages allocated, sitting nearly empty, unfreeable. That is, we could write a sort of bug reproduction showing an error in current (non-compacting) Ruby memory behaviour. “Here’s this bad thing Ruby can do in this specific weird case.” And with compaction, it doesn’t do that.
Or we could look at total memory usage, which is also improved by compaction.
Wait, What’s Compaction Again?
You may recall that Ruby divides memory allocation into tiny, small and large objects - each object is one of those. Depending on which type it is, the object will have a reference (always), a Slot (except for tiny objects) and a heap allocation (only for large objects.)
The problem is the Slots. They’re slab-allocated in large numbers. That means they’re cheap to allocate, which is good. But then Ruby has to track them. And since Ruby uses C extensions with old C-style memory allocation, it can’t easily move them around once it’s using them. Ruby deals with this by waiting until you’ve free all the Slots in a page (that’s the slab) of Slots, then freeing the whole thing.
That would be great, except… What happens if you free all but one (or a few) Slots in a page? Then you can’t free it or re-use it. It’s a big chunk of wasted memory. It’s not quite a leak, since it’s tracked, but Ruby can’t free it while there’s even a single Slot being used.
Enter the Memory Compactor. I say you “can’t easily move them around.” But with significant difficulty, a lot of tracking and burning some CPU cycles, actually you totally can. For more details I’d recommend watching this talk by Aaron Patterson. He wrote the Ruby memory compactor. It’s a really good talk.
In Ruby 2.7, the memory compactor is something you have to run manually by calling “GC.compact”. The plan (as announced in Nov 2019) is that for Ruby 3.0 they’ll have a cheaper memory compactor that can run much more frequently and you won’t have to call it manually. Instead, it would run on certain garbage collection cycles as needed.
How Would We Check the Memory Usage?
A large, complicated Rails app (cough Discourse cough) tends to have a lot of variability in how much memory it uses. That makes it hard to measure a small-ish change. But a very simple Rails app is much easier.
If you recall, I have a benchmark that uses an extremely simple Rails app. So I added the ability to check the memory usage after it finishes, and a setting to compact memory at the end of its initialisation.
A tiny Rails app will have a lot less to compact - mostly classes and code, so there’s less in a small Rails app. But it will also have a lot less variation in total memory size. Compaction or no, Ruby doesn’t usually free memory back to the operating system (like other dynamic languages), so a lot of what we want to check is whether the total size is smaller after processing a bunch of requests.
A Rails server, if you recall, tends to asymptotically approach a memory ceiling as it runs requests. So there’s still a lot of variation in the total memory usage. But this is a benchmark, so we all know I’m going to be running it many, many times and comparing statistically. So that’s fine.
Methodology
For this post I’m using Ruby 2.7.0-preview3. That’s because memory compaction was added in Ruby 2.7, so I can’t use a released 2.6 version. And as I write this there’s no final release of 2.7. I don’t have any reason to think compaction will change size later, so these memory usage numbers should be accurate for 2.7 and 3.0 also.
I’m using Rails Simpler Bench (RSB) for this (source link). It’s much simpler than Rails Ruby Bench and far more suitable for this purpose.
For now, I set an after_initialize hook in Rails to run when RSB_COMPACT is set to YES and I don’t do that when it’s set to NO. I’m using 50% YES samples and 50% NO samples, as you’d expect.
I run the trials in a random order with a simple runner script. It’s running Puma with a single thread and a single process - I was repeatability far more than I want speed for this. It’s hitting an endpoint that just statically renders a single string and never talks to a database or any external service. This is as simple as a Rails app gets, basically.
Each trial gets the process’s memory usage after processing all requests using Richard Schneeman’s get_process_mem gem. This is running on Linux, so it uses the /proc filesystem to check. Since my question is about how Ruby’s internal memory organisation affects total OS-level memory usage, I’m getting my numbers from Linux’s idea of RSS memory usage. Basically, I’m not trusting Ruby’s numbers because I already know we’re messing with Ruby’s tracking - that’s the whole reason we’re measuring.
And then I go through and analyse the data afterward. Specifically, I use a simple script to read through the data files and compare memory usage in bytes for compaction and non-compaction runs.
The Trials
The first and simplest thing I found was this: this was going to take a lot of trials. One thing about statistics is that detecting a small effect can take a lot of samples. Based on my first fifty-samples-per-config trial, I was looking for a maybe half-megabyte effect in a 71-megabyte memory usage total, and around 350 kilobytes of standard deviation.
Does 350 kilobytes of standard deviation seem high? Remember that I’m measuring total RSS memory usage, which somewhat randomly approaches a memory ceiling, and where a lot of it depends on when garbage collection happened, a bit on memory layout and so on. A standard deviation of 350kb in a 71MB process isn’t bad. Also, that was just initially - the standard deviation goes down as the number of samples goes up, because math.
Similarly, does roughly 500 kilobytes of memory savings seem small? Keep in mind that we’re not changing big allocations like heap allocations, and we’re also not touching cases where Slots are already working well (e.g. large numbers of objects that are allocated together and then either all kept or all freed.) The only case that makes much of a difference is where Rails (very well-tuned Ruby code) is doing something that doesn’t work well with Ruby’s memory system. This is a very small Rails app, and so we’re only getting some of the best-tuned code in Ruby. Squeezing out another half-megabyte for “free” is actually pretty cool, because other similar-sized Ruby programs probably get a lot more.
So I re-ran with 500 trials each for compaction and no compaction. That is, I ran around 30 seconds of constant HTTP requests against a server about a thousand more times, then checked the memory usage afterward. And then another 500 trials each.
Yeah, But What Were the Results?
After doing all those measurements, it was time to check the results again.
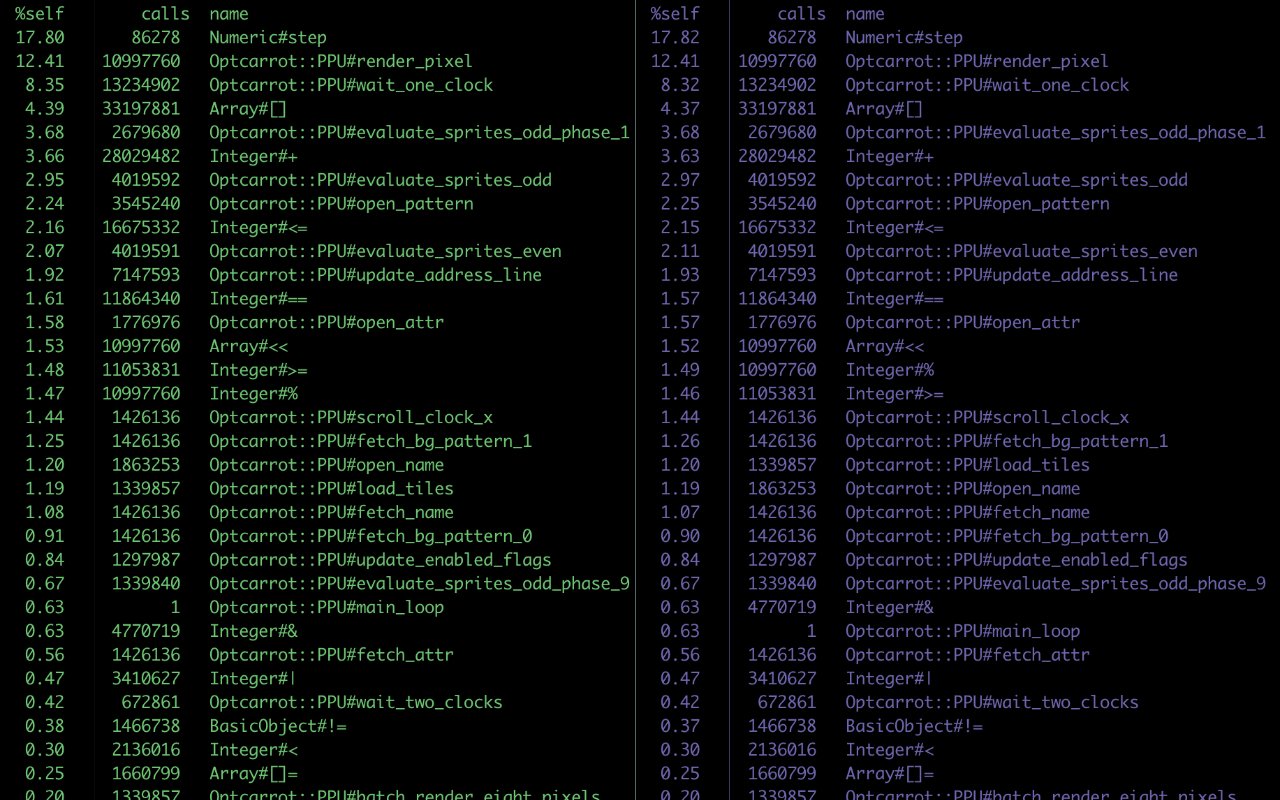
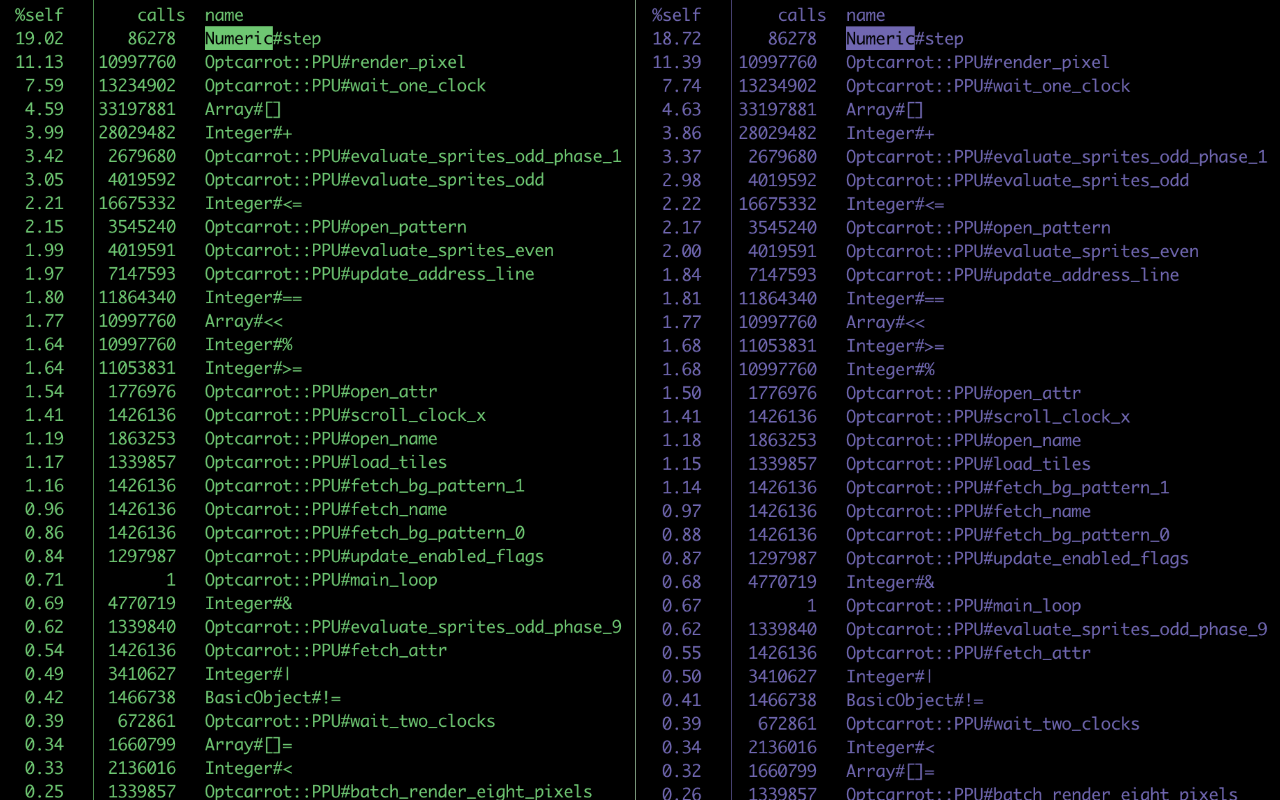
You know those pretty graphs I often put here? This wasn’t really conducive to those. Here’s the output of my processing script in all its glory:
Compaction: YES mean: 70595031.11787072 median: 70451200.0 std dev: 294238.8245869074 -------------------------------- Compaction: NO mean: 71162253.14068441 median: 70936576.0 std dev: 288533.47219640197 --------------------------------
It’s not quite as pretty, I’ll admit. But with a small amount of calculation, we see that we save around 554 kilobytes (exact: 567,222 bytes) per run, with a standard deviation of around 285 kilobytes.
Note that this does not involve ActiveRecord or several other weighty parts of Rails. This is, in effect, the absolute minimum you could be saving with a Rails app. Overall, I’ll take it.
Did you just scroll down here hoping for something easier to digest than all the methodology and caveats? That’s totally fair. I’ll just add a little summary line, my own equivalent of “and thus, the evil princess was defeated and the wizard was saved.”
And so you see, with memory compaction, even the very smallest Rails app will save about half a megabyte. And as Aaron says in his talk, the more you use, the more you save!