

Measuring Rails Overhead
/We all know that using Ruby on Rails is slower than just plain Rack. After all, Rack is the simplest, most bare-bones web interface in Ruby, unless you’re willing to do without compatibility between app servers (or unless you’re writing your own.)
But how much overhead does Rails add? Is it getting less as Ruby gets faster?
I’m working with a new, simpler Rails benchmark lately. Let’s see what it can tell us on this topic.
Easy Does It
If we want to measure Rails overhead, let’s start simple - no concurrency (one thread, one process) and a simple Rails “hello, world”-style app, meaning a single route that returns a static string.
That’s pretty easy to measure in RSB. I’ll assume Puma is a solid choice of app server - not necessarily the best possible, but more representative than WEBrick. I’ll also use an Amazon EC2 m4.2xlarge dedicated instance. It’s my normal Rails Ruby Bench baseline, and a solid choice that a modestly successful Ruby startup would be likely to use. I’ll use Rails version 4.2 - not the newest or the best. But it’s the last version that’s still compatible with Ruby 2.0.0, which we need.
We’ll look at one of each Ruby minor version from 2.0 through 2.6. I like to start with Ruby 2.0.0p0 since it’s the baseline for Ruby 3x3. Here are throughputs that RSB gets for each of those versions:

That looks decent - from around 760 iters/second for Ruby 2.0 to around 1000 iters/second for Ruby 2.6. Keep in mind that this is a single-threaded benchmark, so the server is only using one core. You can get much faster numbers with more cores, but then it’s harder to tell exactly what’s going on. We’ll start simple.
Now: how much of that overhead is Ruby on Rails, versus the application server and so on? The easiest way to check that is to run a Rack “hello, world” application with the same configuration and compare it to the Rails app.
Here’s the speed for that:

Once again, not bad. You’ll notice that Rails is quite heavy here - the Rack-based app runs far faster. Rails is really not designed for “hello, world”-type applications, just as you’d expect. But we can do a simple mathematical trick to subtract out the Puma and Rack overhead and get just the Rails overhead:

Then we can subtract the Puma and app server overhead from Rails. Here’s what that looks like when we do it once for each Ruby version.
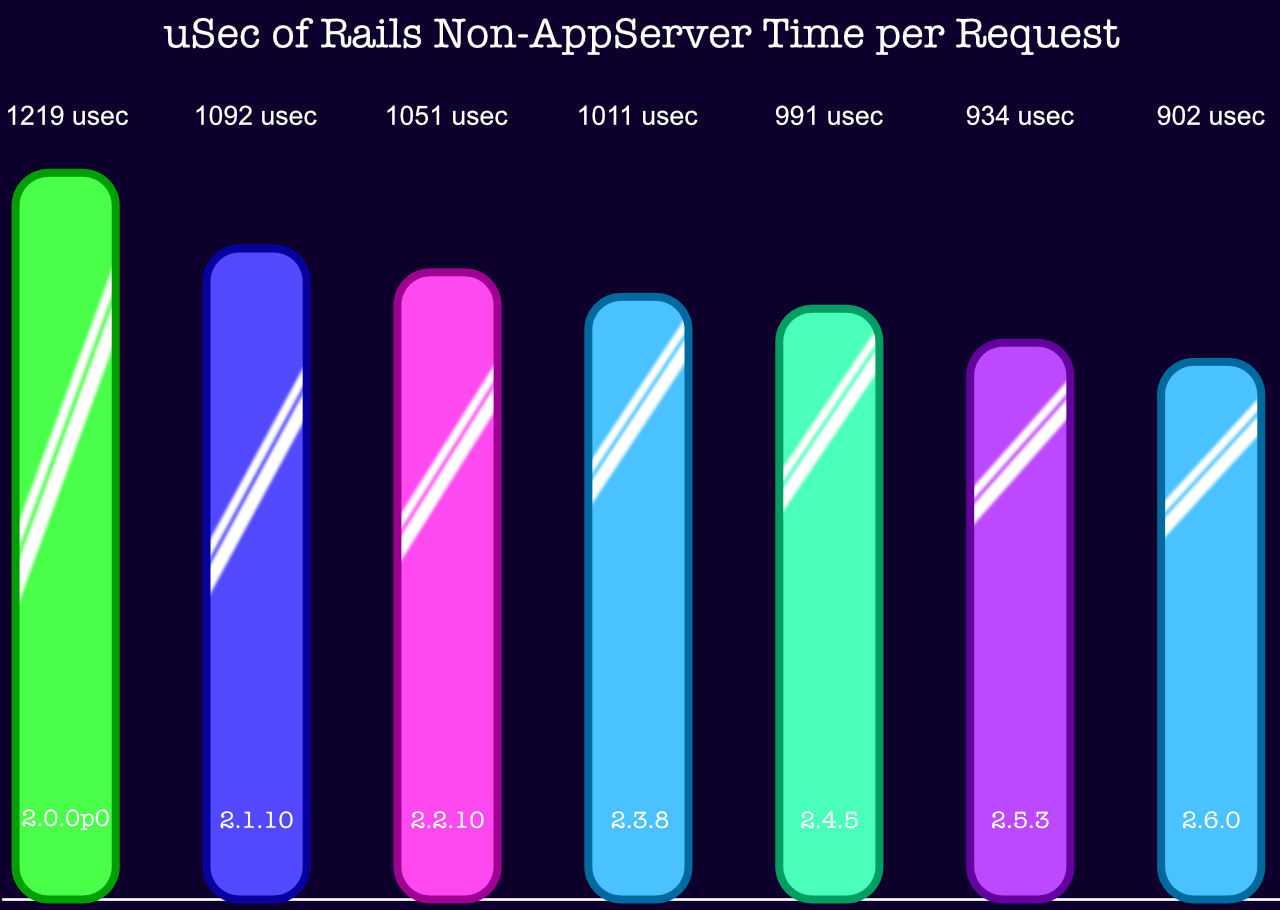
And now you can see how long Rails adds to the execution time of each route in your Rails application! You’ll notice the units are “usec”, or microseconds. So to round shamelessly, Rails adds around 1 millisecond (1/1000th of a second) to each request. The Rack requests above happened at more like 12,000/second, or around 83 usec per request — that’s added to the Rails time in the last graph, not subtracted from it.
Other Observations
When you measure, you usually get roughly what you were looking for - in this case, we answered the question, “how much time does Rails take for each request?” But you often get other interesting information as well.
In this case, we get some interesting data points on what gets faster with newer Ruby versions.
You may recall that Discourse, a big Rails app, running with high concurrency, gets about 72% faster from Ruby 2.0.0p0 to Ruby 2.6. Some of the numbers with OptCarrot show huge speedups, 400% and more in a few specific configurations.
The numbers above are less exciting, more in the neighborhood of 30% speedup. Heck, Rack gets only 16%. Why?
I’ll let you in on a secret - when I time with WEBrick instead of Puma, it gets 74% faster. And after that 74% speedup, it’s still slower than Puma.
Puma uses a reactor and the libev event library to spend most of its time in highly-tuned C code in system libraries. As a result, it’s quite fast. It also doesn’t really get faster when Ruby does — that’s not where it spends its time.
WEBrick can get much faster because it’s spending lots of time in Ruby… But only to approach Puma, not really to surpass it.
OptCarrot can do even better - it’s performance-intensive all-Ruby code, it’s processor-bound, and a lot of optimizations are aimed at exactly what it’s doing. So it can make huge gains - tripling its speed or more. You’ll also notice if you explore OptCarrot a bit that it’s harder to see those huge gains if it’s running in optimized mode. There’s just less fat to cut. That should make sense, intuitively.
And highly-tuned code that’s still basically Ruby, like the per-request Rails code, is in between. In this case, you’re seeing it gain around 30%, which is much better than nothing. In fact, it’s quite respectable as a gain to highly-tuned code written in a mature programming language. That 30% savings will save a lot of processor cycles for a lot of Rails users. It just doesn’t make a stunning headline.
Conclusions
We’ve checked Rails’ overhead: it’s around 900usec/request for modern Ruby.
We’ve checked how it’s improved: from about 1200 usec to 900 usec since Ruby 2.0.0p0.
And we’ve observed the range of improvement in Ruby code: glue code like Puma only gains around 16% from Ruby 2.0.0p0 to 2.6, because it barely spends any time in Ruby. Your C extensions aren’t going to magically get faster because they’re waiting on C, not Ruby. And it’s quite usual to get around 72%-74% on “all-Ruby” code, from Discourse to WEBrick. But only in rare CPU-heavy cases are you going to see OptCarrot-like gains of 400% or more… And even then, only if you’re running fairly un-optimized code.
Here’s one possible interpretation of that: optimization isn’t really to take your leanest, meanest, most carefully-tuned code and make it way better. Most optimization lets you write only-okay code and get closer to those lean-and-mean results without as much effort. It’s not about speeding up your already-fastest code - it’s about speeding you up in writing the other 95% of your code.