

Benchmarking Ruby's Heap: malloc, tcmalloc, jemalloc
/Last week's post talked about different kinds of Ruby objects: some are contained in the 64-bit reference directly, some use up a 40-byte "Slot", and some use a Slot and a chunk of heap. Let's talk about that last set of objects.
"The Heap" isn't specifically a Ruby concept. It's a standard part of Unix processes. Other than garbage collection, Ruby doesn't do much that's special or unusual with the Heap in its processes. So: what's there to talk about?
It turns out that the heap does get managed. The C standard library has a "normal" malloc. But memory allocation is like everything else run by programmers: you have a bunch of different choices with subtle differences between them. And so you have several memory allocators to choose from. There are smart folks who strongly favor nonstandard allocators like tcmalloc and jemalloc, and get great results with them.
Also, I haven't measured anything with RailsRubyBench in a little while. I get itchy. You know how it goes.
(Do you just want to see the pretty graph? I totally understand. Scroll down, it's near the bottom after the explanation.)
What Does Malloc Do?
I won't dive too deeply into malloc -- the information is out there, and mostly it's not what you need to know for Ruby. But let's hit the basics.
Your process uses memory "pages" which it requests from the operating system. They're usually 4 kibibytes (4096 bytes), though it can get complicated. Your memory allocator figures out when to ask the operating system for new pages. It manages chunks of memory that usually aren't 4096 bytes, the ones your program asks for. If you return them later, it manages those too. So it often winds up with a kind of memory Swiss cheese as your Ruby program asks for various sizes of objects and hands them back in a different order.
(Doesn't Ruby use garbage collection? Sure. But when it frees your object automatically, it turns around and frees up that memory using whatever malloc implementation it's using. Just because you don't manually free the memory doesn't mean Ruby doesn't do that. Ruby is written in C, and behaves like it.)
Malloc needs to keep a list of what memory is used and free. It needs to update that list when you allocate or free memory in the Heap. You're asking for more Heap when your process asks for a Page full of Slots. But you don't touch the Heap when you use a Slot in a Page that Ruby already has.
What's the Difference?
If you enjoy reading C code, may I recommend the Dan Luu tutorial on implementing a really basic malloc? It's a great way to start thinking about what malloc does and how it does it. Of course, real malloc is normally a lot more complicated, but it's a good start.
There are a few different commonly-available malloc implementations, aside from whatever version came as part of your C standard library.
The two we'll talk about today are called tcmalloc and jemalloc. You can build or run Ruby with either one. Tcmalloc is part of the Google Performance Tools suite and keeps a thread-local cache for each malloc so you don't have to go to a single big pool of memory for every allocation on every thread. That's not going to help much for an only-processes Ruby application that doesn't use threads... But Rails Ruby Bench uses threading pretty heavily, so you'd think tcmalloc could help a lot.
Jemalloc is the old FreeBSD allocator, separated from FreeBSD. Like tcmalloc, it keeps per-thread chunks of memory and tries to avoid memory fragmentation. It comes highly recommended by Ruby performance luminaries like Nate Berkopec. Both allocators are good, and there are a few interesting differences between them.
So, shall we have a speed shootout?
How Fast?
I'm going to use Ruby 2.5.0 and Rails Ruby Bench for this. So I'm answering the question, "for a big concurrent Rails benchmark, what's the difference in total speed/throughput?" Memory benchmarks are a little odd this way. I'm measuring speed, but making some changes that clearly affect total memory usage. But the memory usage is basically capped by the fact that it's a single m4.2xlarge dedicated EC2 instance running ten Rails processes. So this benchmark answers how better memory efficiency translates into speed with a constant amount of memory, not how little memory you can use.
(Why do we care exactly what/how this measures? For starters, because there's probably a better way to tune Puma for lower memory usage per process. This shootout probably understates how much faster a more efficient malloc is, because it starts with a benchmark that has been carefully tuned for normal system malloc. You might be able to get better throughput with more Puma processes, for instance, or more threads per process. This benchmark doesn't measure that.)
So, what do we measure? I started with normal Ruby 2.5.0, and Ruby 2.5.0 with jemalloc and tcmalloc. I also tried using the memory environment variable settings the page suggested for tcmalloc, but they're entirely within the margin of error - in this benchmark, warmup is serving the same purpose, so on-boot memory settings don't matter enough to be measurable.
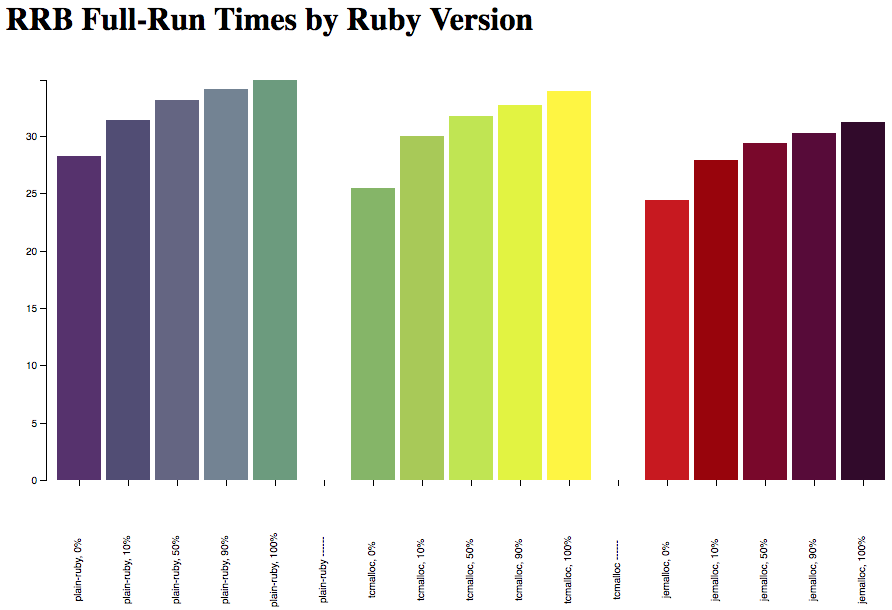
These are full-run times with Rails Ruby Bench, measured in seconds. In case you're not already familiar with RRB, I'm running Discourse with 10 processes and 60 threads on an EC2 dedicated m4.2xlarge instance in a don't-use-the-network configuration to reduce variation. It's a configuration that's meant to answer, "what's the speed difference for a highly-concurrent Rails application, running as hard as my fairly-large EC2 instance can handle?" There's a 30-thread load tester processes running 6000 requests/batch, and each of these configurations was tested for 60 batches. 60 batches of 6,000 requests gives 360,000 HTTP requests for each configuration. I throw out any batch that has an HTTP error, but in this case none of the 180 batches got any errors. It does happen for some benchmarks because HTTP is like that.
That graph is reasonably pretty, but it's hard to pull a specific percentage out. Let's put the numbers in a table and check percentages, shall we?
| Percentile | CRuby 2.5.0 | 2.5.0 w/ jemalloc | 2.5.0 w/ tcmalloc | speedup w/ tcmalloc | speedup w/ jemalloc |
|---|---|---|---|---|---|
| 0% | 28.22 sec | 24.45 sec | 25.45 sec | 9.82% | 13.38% |
| 10% | 31.41 sec | 27.86 sec | 30.03 sec | 4.40% | 11.30% |
| 50% | 33.13 sec | 29.40 sec | 31.72 sec | 4.27% | 11.25% |
| 90% | 34.12 sec | 30.28 sec | 32.70 sec | 4.15% | 11.25% |
| 100% | 34.87 sec | 31.17 sec | 33.90 sec | 2.80% | 10.62% |
Overall we're getting about an 11% speedup with jemalloc here, and a much more variable speedup, between 3% and 10%, with tcmalloc. That makes sense, and matches the reports I've heard of both jemalloc and tcmalloc. Note that this is with no additional tuning (e.g. no change in the number of processes or threads,) and none of these got a single server error in the 360,000 requests they each handled. So: reasonably solid.
(I've run these numbers and gotten as low as 9% speedup for jemalloc before as well. But the speedup is still in a similar range.)
When I check throughput rather than runtimes I usually get a smaller speedup - total throughput uses the slowest of the runs as the total time, so it nearly always shows less speedup. What's interesting here is that that's clearly true of tcmalloc... But jemalloc gets great results on throughput, suggesting a very consistent speedup (as you see above as well):
| CRuby 2.5.0 | jemalloc | tcmalloc | increase w/ tcmalloc | increase w/ jemalloc | |
|---|---|---|---|---|---|
| Median Throughput | 175.13 req/sec | 197.49 req/sec | 183.33 req/sec | 4.68% | 12.77% |
Conclusions
It looks like the jemalloc advocates have a darn good point. That makes sense. Richard Schneeman and Nate Berkopec are the kind of folks who would know. It looks like jemalloc gives conservatively an 11% speedup for a big concurrent Rails app. Tcmalloc is more variable but still hits 4%-9% speedup or so, which is nothing to sneeze at. Remember that this is overall speedup - not just when allocating memory, but for the full Rails app's runtime and throughput.
Among other things, this should tell you that heap management is important in Ruby. If you weren't seeing many bytes allocated on the heap, or if heap management was really fast, there wouldn't be a 10% speedup to give!