Recently the brilliant and accomplished Chris Seaton asked me what the difference was between Rails Ruby Bench and the normal Discourse benchmarks, as seen on ruby-bench.org.
Plus I keep writing about RRB and linking to the code on GitHub. That's not terrible, but it's not exactly friendly. So let's talk: what is Rails Ruby Bench? Why should you care?
(Spoiler: if you mostly care about Ruby on Rails performance on a big server or VM, Rails Ruby Bench is the closest to "your" benchmark for Ruby that you'll find.)
The Very Basics: What Is RRB?
Rails Ruby Bench uses Discourse, a real-world Ruby on Rails app, and a simulated realistic workload to benchmark the speed of Ruby. So: what is "real-world"? Let alone "simulated realistic workload?"
First off, if you have 40 minutes here's what I said about that at RubyKaigi in Hiroshima in 2017, along with a lot of the information about Ruby's speed that came from RRB. I'm pretty proud of it!
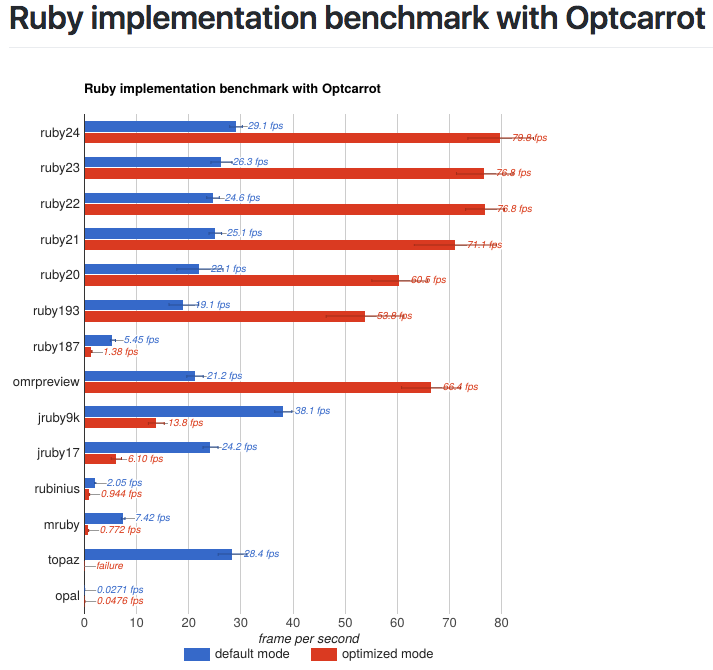
But for the quick version: Ruby benchmarks historically tend to be about the language's raw speed, and tend to be pretty small. OptCarrot is a great example - a very solid benchmark that still doesn't use Rails or concurrency or much garbage collection. A benchmark like that is really easy to work from and it has a lot to do with the language itself. That's exactly the kind of major benchmark you want if you're implementing a language. Which is why they did!
But when you're telling the community about your speedups, folks want to know: but what about lots of threads or processes? What about I/O-bound and memory-bound applications? And in Ruby they ask, "but what about Ruby on Rails?"
Those are great questions. RRB tries hard to answer them.
How Does It Do That?
Rails Ruby Bench uses a real-world, typical, in-production open-source Ruby on Rails app as its basis. That would be Discourse, software for forums built by a real commercial company. It has all the little hairy bits of DDOS-protection and security and stuff that Real Apps™ do and benchmarks usually do not. Then it generates a lot of repeatably-random but realistic HTTP requests browsing through topics, saving drafts, posting comments and so on. It mimics a lot of users doing their thing and determines how much load Discourse can process with that Ruby version, basically.
RRB uses a large dedicated EC2 instance and loads it up to full capacity, running flat-out. Then it measures how fast 10 processes and 60 threads can process the requests. This is a pretty realistic setup and looks a lot like how small-to-mid-size startups do it and what they care about.
It's a benchmark, so what does it do badly? It runs the load-test process and the database on the same instance as the benchmark - that's great for low-variance results (no network, no noisy neighbors) but is absolutely not a realistic setup. It also runs with only a single application server and no load balancer, so it tests nothing about the scaling of load-balancing or the database. That's because it's a benchmark for the Ruby language, and neither of those components normally use Ruby. Similarly, it runs without a reverse-proxy in front (no NGinX) and the load-tester doesn't request static files -- I want to test Ruby, not NGinX.
Other good things about RRB: its basic setup has been vetted by luminaries like Nate Berkopec, Richard Schneeman, the aforementioned Chris Seaton and others. I've changed a number of things to reflect their observations and/or my previous screwups. So it's battle-tested.
It's also shown some fairly interesting things about Ruby's speed. Again, I recommend my RubyKaigi 2017 presentation for even more details.
More for Pedants (Scroll Past If You Don't Care)
What about failed requests? If any request generates a 500-series error I throw away the whole run, normally between 4,000 and 6,000 requests, depending on what's being benchmarked. As Ruby gets faster and I measure smaller effects, the number of HTTP requests per run has to go up to get accurate results.
I most frequently run with one warmup start/stop iteration, and 100 warmup HTTP requests. If I use a different number than that, I'll say so in the specific post about it. It's configurable when you run RRB.
I've used multiple Discourse versions over time, and I update slowly over time. It's hard to keep RRB usable across many Discourse versions as the code and HTTP request format changes -- that's just a hazard of using a real-world app.
Why RRB Is Different
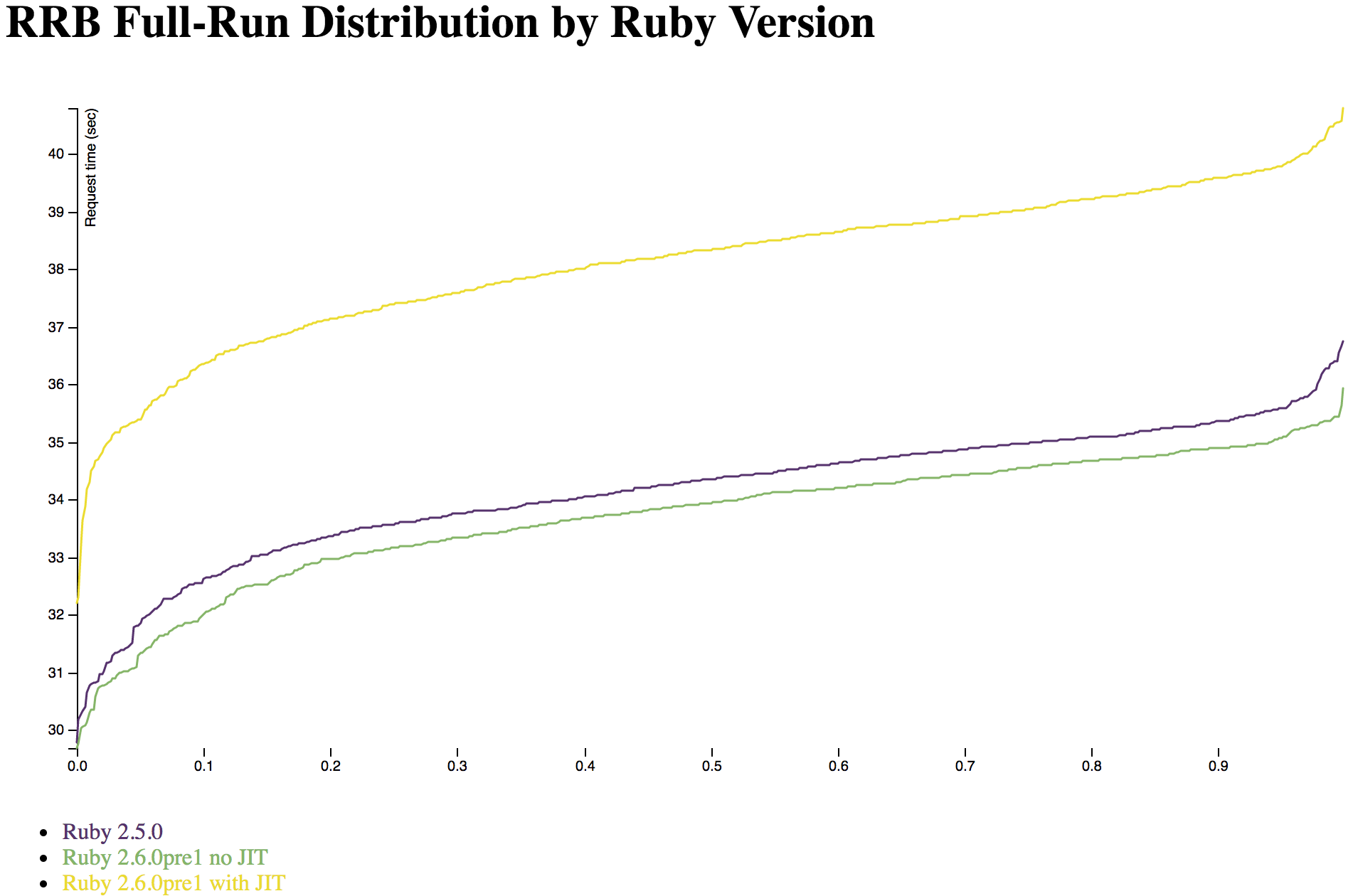
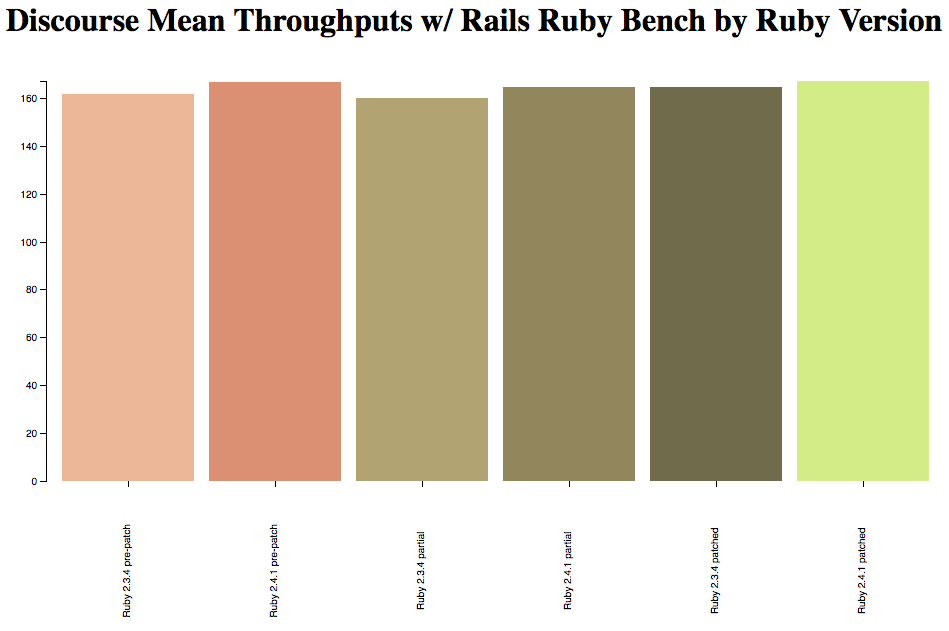
The standard Discourse benchmarks request the same URL many times in a row using ApacheBench, then measures the speed with a simple "best time out of N" metric -- though it also does one run where it measures the memory usage. RRB requests different URLs in different orders with different parameters, which affects the speed of the resulting benchmark and gives a "blended" result from many different URLs. As a result, you'll often see Ruby optimizations where different standard Discourse benchmarks give different amounts of optimization and RRB shows a weighted average of those speedups - sometimes a particular Ruby optimization is much faster for some URLs than others.
Smaller benchmarks like OptCarrot often give very different results than RRB. They tend to measure CPU time, while RRB effectively measures memory and I/O performance as much or more -- it's a bunch of parallel Ruby on Rails processes running in Puma, so CPU time isn't the be-all end-all that you see in a much smaller process.
RRB's primary difference from straight-up I/O or garbage collection benchmarks is that it does measure CPU performance. You might expect Ruby on Rails to not care about CPU performance, and to be purely CPU- and memory-bound, but that's not what RRB's results show. There's plenty of room to optimize Rails by optimizing CPU performance, though that's not the whole story.
Is Rails Ruby Bench All Done Now?
Benchmarks often have a kind of "shelf life" built in - by their nature they show a single metric, and at some point you've gotten nearly all the benefit from that metric.
And RRB has needed some adjustments - Discourse version upgrades, for instance, and running more full runs and more HTTP requests per run.
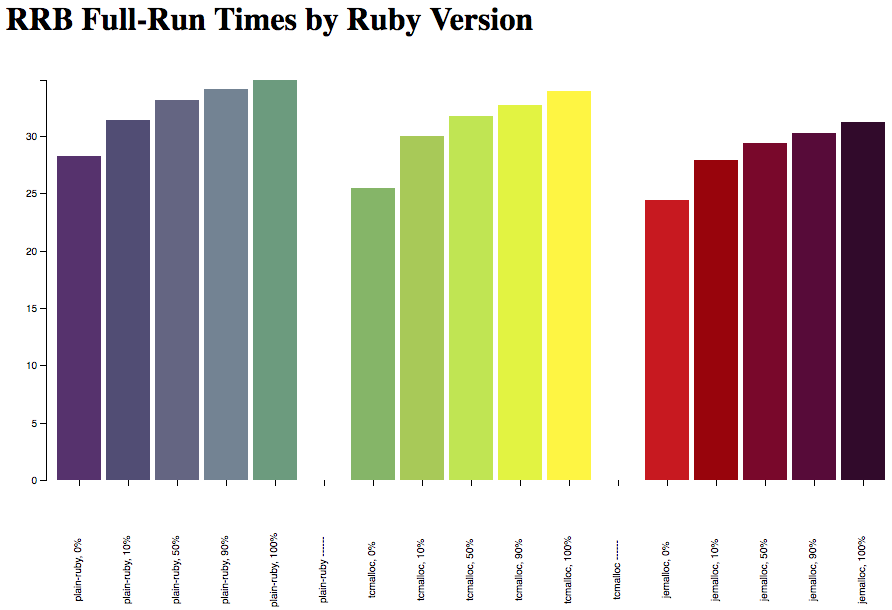
The best evidence I can give that Rails Ruby Bench isn't done is this: I keep finding new, interesting slants for it. Right now (April 2018) I'm trying to measure how much extra speed you can get from Rails by saving memory, and using RRB to do it. I'm trying to figure out how much of MRI's warmup time (it has some!) is from the memory setup and can be removed with environment variables. And soon, RRB will be my go-to metric to see: does JIT speed up Rails? What settings work best?
I think Rails Ruby Bench has more interesting questions to answer in the next year or three. There will, of course, be new efforts of all kinds. And Ruby 3x3 could use more benchmarks as well. But RRB isn't done yet.