
A Composition Regarding Inheritance
/Observations from an Object Oriented Interview
I've had the opportunity to interview a number of candidates for software engineering positions on my team over the past few years. In most of these interviews, I presented the candidate with the same design question: “Let’s say you were designing a traffic simulation. In this simulation, you’ve got a car. It can start, stop, move forward, and move in reverse. Yes, it’s a really boring simulation.” I then asked the candidate to draw this design on a whiteboard. In every interview, I got something that looked like the following picture:

Ok, so far, so good. The candidate thinks of a car as a component in a software system that has capabilities matching my requirements. Then I said, “let’s make this simulation more interesting by including two cars: A and B. Car A and B are similar, but the way car A starts and stops is different from car B. Please update your diagram to show how you would accommodate this requirement while minimizing the amount of repeated code.” In almost every case (and especially when the candidate was fresh out of school) I got the same reaction: a confident smile appeared on the candidate’s face, as if to say, “I’ve done this a million times...textbook object oriented programming.” The candidate returned to the whiteboard and drew this:

“Okay, next task: I want to introduce a new car, say car C. Car C starts like car A, stops like car B, and has its own way of moving forward. Please update the diagram to accommodate this requirement while minimizing the amount of duplicated code.” Long pause. Eyebrows furrowed. At this point, the solutions people gave begin to diverge. C++ folks began struggling with multiple/virtual inheritance, Ruby folks started talking about mixins, and Java folks were stuck. Regardless of the language, the diagram ended up with some more lines to indicate inheritance relationships. I simply proceeded to ask the candidate to add new cars with different combinations of functionality. So for example, I asked the candidate to add car D which moves forward the same way as C, starts like car A, and stops like car B. I continued this process until the whiteboard diagram was an incomprehensible mass of circles and arrows.
My goal in this exercise was not to torture the candidate or to see if they “knew object oriented programming,” but to watch their thought process as they realized that their design approach was brittle and needed some rethinking. At some point the exasperated candidate stopped and said, “there must be a better way,” and this was generally the beginning of a fun and constructive design discussion.
The next question I asked in such interviews was, “can you think of a way to redraw this diagram without any inheritance or mixin relationships.” Many people really struggled with this -- they thought that I was asking a trick question. “Here’s a hint, what if you had a class called Ignition? How would you use it in this picture to remove some of these other class relationships.” This was usually the moment of epiphany for the candidate. The vocabulary of our discussion rapidly expanded from talking about the methods of the Car class to new concepts like Brake, Accelerator, and Transmission. Pretty soon our diagram looked like this:
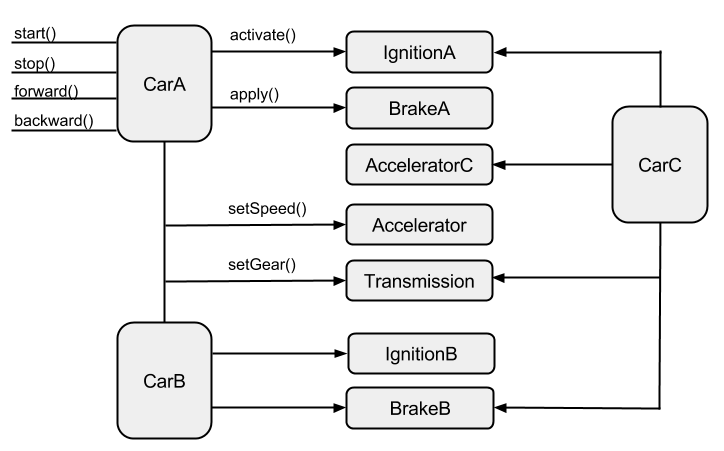
Pretty straight forward. This design approach is called class composition. Many of the candidates said, “wow, that solution should have been obvious to me.” Maybe so, but I must admit that I had their very same approach to design when I first began working at a software company. To some, the software requirements described in the exercise may seem pathological, but this has not been my experience. I feel that the exercise is actually a pretty good picture of the way some of the first software projects that I worked on developed after I graduated. I encountered many of the same frustrations that the candidates I interviewed did, just on a larger scale.
Those who are familiar with Ruby will point out that mixins are another way to meet the requirements of the system described above. For example, we might create Startable, Stoppable, and Movable mixins that could be included in any combination within our different car classes. But, in the context of the interview exercise, I could still push my requirements further. “Okay, let’s say we want a new car X that starts like car A on hot summer days, but starts like car B on cold winter days. Please update your diagram to accommodate this requirement while minimizing the amount of repeated code.” This is trivial with a composition-based design. Our car X just updates its ignition reference from IgnitionA to IgnitionB on cold days. This is more difficult to achieve with Ruby mixins since, again, we declare an explicit class relationship before runtime. Or how about another requirement, “let’s say that the start sequence for car Y begins with the sequence for car A and ends with the sequence for car B.” Again, the mixin relationship represents a design commitment we make up-front that reduces our options later in the game. Traditional inheritance and mixins are very similar in this respect.
Comparing Composition and Inheritance as Design Tools
Why is it that many of us have a tendency to approach design problems using inheritance rather than composition? One reason could be the way object oriented programming is presented in school and in textbooks. Whenever I asked interview candidates why they chose inheritance over composition, the general response was that inheritance describes an is-a relationship and composition describes a has-a relationship. They initially felt that the interview exercise was best suited to an is-a relationship, so that’s what they went with. Indeed, this is exactly how I learned to think about object oriented programming. The problem with this view is that the classification is subjective. You can almost always think of a way to convert an is-a relationship into a has-a relationship and vice-versa, just like I described in my example above.
The is-a/has-a paradigm can give one the impression that composition and inheritance are two similar tools on equal footing that can be used interchangeably to achieve a similar goal. In reality, these tools have very different strengths and are therefore suited to different problems. It is wise, then, to consider these strengths in choosing which tool to apply in a particular situation.
I've already alluded to some of composition’s strengths in the examples above. These include a greater opportunity to defer design commitments and a more natural way to talk about and model the problem space. The first is due to the fact that composed relationships are based on object references, not class references. In the car example above, we refactored our design such that a car is composed of several internal components. In this scheme we have the option of changing the references to these components at any time, including runtime. That is to say, we could design a system in which a car could be reassembled with totally different components all while traveling 80 mph down the highway. That’s pretty powerful. With inheritance, we would either need to stop our software and modify the inheritance hierarchy or, if we were working in Ruby, engage in some metaprogramming wizardry. The point is, with composition we minimize early design commitments and maximize the likelihood we'll be able to accommodate unexpected requirements.
The other strength is somewhat less tangible in a discussion like this, but in my view no less important. Composition is the way we generally think about how systems work in the physical world. It therefore lends itself nicely to the development of clear vocabulary for talking about a problem. If I asked you to tell me how a blender works, you would probably begin by identifying the key components: blade, motor, power cord, switch, carafe, and lid. Each component in the system has a specific job and works in concert with other components in the system. For a given blender use-case, you could draw me a diagram of how the parts interact with one another -- the motor turns the blade, the lid locks into the carafe, the switch opens the flow of electricity through the motor. On the other hand, you could consider an inheritance-based approach. You might begin by describing a blender as a type of kitchen appliance. Appliances consume electricity to perform work, where the work performed depends on the specific type of appliance. In the case of a blender, the work performed is the rotation of a blade to chop or liquify food. While this is a reasonable definition for a blender, it tells us little about what a blender is from an implementation point of view. Based on this description, it would be more difficult to draw a diagram of what happens internally when someone presses the “on” switch.
Our blender discussion brings us back around to the is-a/has-a distinction, but perhaps with the opportunity for a deeper understanding. The composition-based design is better suited for describing how our blender accomplishes its job whereas the inheritance-based design is better suited for defining what a blender is. Do you see the difference? The definition of a blender can apply to a wide range of blender implementations. Silver Bullet and VitaMix are both blenders but they have different implementations. Our view of a blender as the composition of many parts represents the description of a specific blender implementation. Inheritance therefore finds it’s strength in describing the relationships between class interfaces apart from implementation. Composition by its very nature is an implementation detail and finds it’s strength in modeling the implementation of a system. This observation has major implications for software design in explicitly typed languages like C++ and Java. In these languages, we can define a hierarchy of pure interfaces (that is, classes with method definitions but no corresponding implementation). We can then refer to objects at different levels of abstraction in various contexts by moving up or down the interface inheritance chain. The classes which implement these interfaces, however, can follow a different structure and can be changed without modification to the interfaces.
I won't get into a detailed discussion of interface-based design here -- it’s a topic that deserves it’s own discussion. I expect that most of the people reading this article are Rubyists. Ruby does not provide an explicit interface concept so the benefits of inheritance for interface-based design are diminished. In the Ruby realm I most often see inheritance applied as a method of code reuse. While code reuse is certainly achievable with inheritance, I hope our discussion so far has provided some convincing evidence that this is not what it excels at -- just consider the frustrated interview candidate from the beginning of this article. Composition for code reuse is more flexible than inheritance and typically comes at little cost.
Okay, so what are the strengths of inheritance in a language like Ruby? I view inheritance in Ruby as a tool of convenience; one that can reduce boilerplate code in cases where several classes share the same method signatures. Consider again the traffic simulation design in my interview question. Each type of car in this example delegates its methods directly to the internal components. This leaves us with a bunch of classes that repeat the same delegation pattern in each method, just with different types of components. This boilerplate code can be removed with the creation of a base class which operates on components provided by subclasses. Notice that we’ve used composition and inheritance together to achieve a flexible and convenient design.

That said, I think there is an even better approach that does not use inheritance if our design does not require a separate class for each type of car. In this case, we can implement a single car class and a car factory that builds cars. The car factory creates different configurations of components depending on what behavior we want in our car and injects them during creation of the car object. See the figure below:

What about the role of mixins in Ruby? Again, in my view mixins provide a measure of convenience, but do not represent a tool that is well suited as the foundation of a system’s design. The Enumerable mixin is a good example to consider. The Enumerable module in Ruby requires that classes which include it implement the each method (and optionally the <=> method). It uses these methods to provide a rich set of traversal, sorting, and searching methods in the including class. Ruby mixes the Enumerable methods into several basic data types including arrays, hashes, and ranges. Working with these types is quite pleasant since they allow all of these methods to be called directly on the objects themselves and allow for several method calls to be chained together. Most people would probably see the Enumerable module as a great example of code-reuse, but I disagree. The same degree of code-reuse can be achieved through simple class methods within a module. Here’s what the call to any? would look like if Enumerable were written in this way:
Enumerable::any?(numbers) { |number| number > 10 }
The main benefit of the mixin approach is ease-of-use. It is more natural for a developer to call the methods directly on the objects, especially when several method calls need to be chained together. Calling class methods in a module is still doable, but would be quite cumbersome in such cases. So the advantages we see in the Enumerable mixin example focus on syntactic niceties. They help developers read and write code (and this is certainly important!), but they do not significantly contribute to a developer’s conceptual understanding of a system, which I believe should be considered as a first priority when designing software.
Concluding Thoughts
The longer I work with object oriented programming languages, the more clearly I see a priority in tools these languages have to offer. In my opinion, composition is the bread and butter of design tools. It’s the tool I reach for first when I’m trying to model the solution for a problem. Doing this allows me to develop meaningful vocabulary for talking about each aspect of the solution. I find that I can draw diagrams showing clear interactions between components and this allows me to verify my understanding of the solution before I spend time implementing it. Once I have implemented my solution using composition, I sometimes notice repeated or excessive boilerplate code. In such cases, I will turn to my tools of convenience: inheritance and modules (domain specific languages and metaprogramming also fall into this category for me). These tools are the icing on the cake. The system can be understood without them, but they can make using or extending the system more pleasant.
When I first learned about object oriented programming I read a book that made this recommendation: “prefer composition; use inheritance judiciously.” This bit of wisdom stood out to me mainly because I didn’t really understand why I should follow it. I’m sure the book provided some justification regarding flexibility, but not in a way that I could grasp at the time. It was only after several years of pain from ignoring this advice that I began to see the basis for it. My hope in writing this article is that others would be provoked to careful thought regarding the application of inheritance in object oriented languages and perhaps avoid some of the same frustration I encountered. Thanks for reading!

